1. Introduction
Database Rider aims for bringing DBUnit closer to your JUnit tests so database testing will feel like a breeze!. Here are the main features:
-
JUnit rule to integrate with DBUnit via annotations:
@Rule public DBUnitRule dbUnitRule = DBUnitRule.instance(jdbcConnection);(1) @Test @DataSet(value = "datasets/yml/users.yml") public void shouldSeedDataSet(){ //database is seed with users.yml dataset }1 The rule depends on a JDBC connection. -
CDI integration via interceptor to seed database without rule instantiation;
-
JSON, YAML, XML, XLS, and CSV support;
-
Configuration via annotations or yml files;
-
Cucumber integration;
-
Multiple database support;
-
Date/time support in datasets;
-
Scriptable datasets with groovy and javascript;
-
Regular expressions in expected datasets;
-
JUnit 5 integration;
-
Lot of examples.
The project is composed by 5 modules:
2. Seeding database
2.1. Seed database with DBUnit Rule
JUnit4 integrates with DBUnit through a JUnit rule called DBUnitRule which reads @Dataset annotations in order to prepare the database state using DBUnit behind the scenes.
| The rule just needs a JDBC connection in order to be created. |
Dependencies
To use it add the following maven dependency:
<dependency>
<groupId>com.github.database-rider</groupId>
<artifactId>rider-core</artifactId>
<version>1.44.1-SNAPSHOT</version>
<scope>test</scope>
</dependency>- Given
-
The following junit rules
- And
-
The following dataset
- When
-
The following test is executed:
| Source code of the above example can be found here. |
- Then
-
The database should be seeded with the dataset content before test execution
2.2. Seed database with DBUnit Interceptor
DBUnit CDI[1] integration is done through a CDI interceptor which reads @DataSet to prepare database in CDI tests.
Dependencies
To use this module just add the following maven dependency:
<dependency>
<groupId>com.github.database-rider</groupId>
<artifactId>rider-cdi</artifactId>
<version>1.44.1-SNAPSHOT</version>
<scope>test</scope>
</dependency>- Given
-
DBUnit interceptor is enabled in your test beans.xml:
|
Your test itself must be a CDI bean to be intercepted. if you’re using Deltaspike test control just enable the following property in deltaspike.testcontrol.use_test_class_as_cdi_bean=true
|
- And
-
The following dataset
- When
-
The following test is executed:
| Source code of the above example can be found here. |
Since v1.8.0 you can also use com.github.database.rider.cdi.api.DBRider annotation to enable database rider, both activate the DBUnitInterceptor. |
- Then
-
The database should be seeded with the dataset content before test execution
2.3. Seed database with JUnit 5 extension
DBUnit is enabled in JUnit 5 tests through an extension named DBUnitExtension.
Dependencies
To use the extension just add the following maven dependency:
<dependency>
<groupId>com.github.database-rider</groupId>
<artifactId>rider-junit5</artifactId>
<version>1.44.1-SNAPSHOT</version>
<scope>test</scope>
</dependency>- Given
-
The following dataset
- When
-
The following junit5 test is executed
| Source code of the above example can be found here. |
|
Another way to activate DBUnit in JUnits 5 test is using @DBRider annotation (at method or class level):
|
| The same works for SpringBoot projects using JUnit5, see an example project here. |
- Then
-
The database should be seeded with the dataset content before test execution
2.4. Seeding database in BDD tests with Rider Cucumber
DBUnit enters the BDD world through a dedicated JUNit runner which is based on Cucumber and Apache DeltaSpike.
This runner just starts CDI within your BDD tests so you just have to use Database Rider CDI interceptor on Cucumber steps, here is the so called Cucumber CDI runner declaration:
package com.github.database.rider.examples.cucumber;
import com.github.database.rider.cucumber.CdiCucumberTestRunner;
import cucumber.api.CucumberOptions;
import org.junit.runner.RunWith;
@RunWith(CdiCucumberTestRunner.class)
@CucumberOptions(
features = {"src/test/resources/features/contacts.feature"},
plugin = {"json:target/cucumber.json"}
//glue = "com.github.database.rider.examples.glues"
)
public class ContactFeature {
} As cucumber doesn’t work with JUnit Rules, see this issue, you won’t be able to use Cucumber runner with DBUnit Rule, but you can use DataSetExecutor in @Before, see example here. |
Dependencies
Here is a set of maven dependencies needed by Database Rider Cucumber:
| Most of the dependencies, except CDI container implementation, are brought by Database Rider Cucumber module transitively. |
<dependency>
<groupId>com.github.database-rider</groupId>
<artifactId>rider-cucumber</artifactId>
<version>1.44.1-SNAPSHOT</version>
<scope>test</scope>
</dependency><dependency> (1)
<groupId>info.cukes</groupId>
<artifactId>cucumber-junit</artifactId>
<version>1.2.4</version>
<scope>test</scope>
</dependency>
<dependency> (1)
<groupId>info.cukes</groupId>
<artifactId>cucumber-java</artifactId>
<version>1.2.4</version>
<scope>test</scope>
</dependency>| 1 | You don’t need to declare because it comes with Database Rider Cucumber module dependency. |
<dependency> (1)
<groupId>org.apache.deltaspike.modules</groupId>
<artifactId>deltaspike-test-control-module-api</artifactId>
<version>${ds.version}</version>
<scope>test</scope>
</dependency>
<dependency> (1)
<groupId>org.apache.deltaspike.core</groupId>
<artifactId>deltaspike-core-impl</artifactId>
<version>${ds.version}</version>
<scope>test</scope>
</dependency>
<dependency> (1)
<groupId>org.apache.deltaspike.modules</groupId>
<artifactId>deltaspike-test-control-module-impl</artifactId>
<version>${ds.version}</version>
<scope>test</scope>
</dependency>
<dependency> (2)
<groupId>org.apache.deltaspike.cdictrl</groupId>
<artifactId>deltaspike-cdictrl-owb</artifactId>
<version>${ds.version}</version>
<scope>test</scope>
</dependency>
<dependency> (2)
<groupId>org.apache.openwebbeans</groupId>
<artifactId>openwebbeans-impl</artifactId>
<version>1.6.2</version>
<scope>test</scope>
</dependency>| 1 | Also comes with Rider Cucumber. |
| 2 | You can use CDI implementation of your choice. |
- Given
-
The following feature
- And
-
The following dataset
- And
-
The following Cucumber test
- When
-
The following cucumber steps are executed
| Source code for the example above can be found here. |
- Then
-
The database should be seeded with the dataset content before step execution
3. DataSet creation
3.1. Creating a YAML dataset
YAML stands for yet another markup language and is a very simple, lightweight yet powerful format.
| YAML is based on spaces indentation so be careful because any missing or additional space can lead to an incorrect dataset. |
| Source code of the examples below can be found here. |
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
The database should be seeded with the dataset content before test execution
3.2. Creating a JSON dataset
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
The database should be seeded with the dataset content before test execution
3.3. Creating a XML dataset
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
The database should be seeded with the dataset content before test execution
4. Configuration
4.1. DataSet configuration
DataSet configuration is done via @DataSet annotation at class or method level:
@Test
@DataSet(value ="users.yml", strategy = SeedStrategy.UPDATE,
disableConstraints = true,cleanAfter = true,
useSequenceFiltering = true, tableOrdering = {"TWEET","USER"},
executeScriptsBefore = "script.sql", executeStatementsBefore = "DELETE from USER where 1=1"
transactional = true, cleanAfter=true)
public void shouldCreateDataSet(){
}Table below illustrate the possible configurations:
| Name | Description | Default |
|---|---|---|
value |
Dataset file name using test resources folder as root directory. Multiple, comma separated, dataset file names can be provided. |
"" |
executorId |
Name of dataset executor for the given dataset. |
DataSetExecutorImpl.DEFAULT_EXECUTOR_ID |
strategy |
DataSet seed strategy. Possible values are: CLEAN_INSERT, INSERT, REFRESH and UPDATE. |
CLEAN_INSERT, meaning that DBUnit will clean and then insert data in tables present in provided dataset. |
useSequenceFiltering |
If true dbunit will look at constraints and dataset to try to determine the correct ordering for the SQL statements. |
true |
tableOrdering |
A list of table names used to reorder DELETE operations to prevent failures due to circular dependencies. |
"" |
disableConstraints |
Disable database constraints. |
false |
cleanBefore |
If true Database Rider will try to delete database before test in a smart way by using table ordering and brute force. |
false |
cleanAfter |
If true Database Rider will try to delete database after test in a smart way by using table ordering and brute force. |
false |
transactional |
If true a transaction will be started before and committed after test execution. |
false |
executeStatementsBefore |
A list of jdbc statements to execute before test. |
{} |
executeStatementsAfter |
A list of jdbc statements to execute after test. |
{} |
executeScriptsBefore |
A list of sql script files to execute before test. Note that commands inside sql file must be separated by |
{} |
executeScriptsAfter |
A list of sql script files to execute after test. Note that commands inside sql file must be separated by |
{} |
4.2. DBUnit configuration
DBUnit, the tool doing the dirty work the scenes, can be configured by @DBUnit annotation (class or method level) and dbunit.yml file present in test resources folder.
@Test
@DBUnit(cacheConnection = true, cacheTableNames = false, allowEmptyFields = true,batchSize = 50)
public void shouldLoadDBUnitConfigViaAnnotation() {
}Here is a dbunit.yml example, also the default values:
cacheConnection: true (1) cacheTableNames: true (2) leakHunter: false (3) caseInsensitiveStrategy: !!com.github.database.rider.core.api.configuration.Orthography 'UPPERCASE' (4) properties: batchedStatements: false (5) qualifiedTableNames: false (6) caseSensitiveTableNames: false (7) batchSize: 100 (8) fetchSize: 100 (9) allowEmptyFields: false (10) escapePattern: (11) connectionConfig: (12) driver: "" url: "" user: "" password: ""
| 1 | Database connection will be reused among tests |
| 2 | Caches table names to avoid query connection metadata unnecessarily |
| 3 | Activate connection leak detection. In case a leak (open JDBC connections is increased after test execution) is found an exception is thrown and test fails. |
| 4 | When caseSensitiveTableNames is false will apply letter case based on configured strategy. Valid values are UPPERCASE and LOWERCASE. |
| 5 | Enables usage of JDBC batched statement |
| 6 | Enable or disable multiple schemas support. If enabled, Dbunit access tables with names fully qualified by schema using this format: SCHEMA.TABLE. |
| 7 | Enable or disable case sensitive table names. If enabled, Dbunit handles all table names in a case sensitive way. |
| 8 | Specifies the size of JDBC batch updates |
| 9 | Specifies statement fetch size for loading data into a result set table. |
| 10 | Allow to call INSERT/UPDATE with empty strings (''). |
| 11 | Allows schema, table and column names escaping. The property value is an escape pattern where the ? is replaced by the name. For example, the pattern "[?]" is expanded as "[MY_TABLE]" for a table named "MY_TABLE". The most common escape pattern is ""?"" which surrounds the table name with quotes (for the above example it would result in ""MY_TABLE""). As a fallback if no questionmark is in the given String and its length is one it is used to surround the table name on the left and right side. For example the escape pattern """ will have the same effect as the escape pattern ""?"". |
| 12 | JDBC connection configuration, it will be used in case you don’t provide a connection inside test (except in CDI test where connection is inferred from entity manager). |
@DBUnit annotation takes precedence over dbunit.yml global configuration which will be used only if the annotation is not present. |
|
Since version 1.1.0 you can define only the properties of your interest, example: cacheConnection: false properties: caseSensitiveTableNames: true escapePattern: ""?"" |
5. DataSet assertion
5.1. Assertion with yml dataset
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
Test must pass because database state is as in expected dataset.
5.2. Assertion with regular expression in expected dataset
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
Test must pass because database state is as in expected dataset.
5.3. Database assertion with seeding before test execution
- Given
-
The following dataset
- And
-
The following dataset
- When
-
The following test is executed:
- Then
-
Test must pass because database state is as in expected dataset.
5.4. Failing assertion
- Given
-
The following dataset
- When
-
The following test is executed:
- Then
-
Test must fail with following error:
5.5. Assertion using automatic transaction
- Given
-
The following dataset
- When
-
The following test is executed:
Transactional attribute will make Database Rider start a transaction before test and commit the transaction after test execution but before expected dataset comparison. |
- Then
-
Test must pass because inserted users are committed to database and database state matches expected dataset.
6. Dynamic data using scritable datasets
7. Database connection leak detection
7.1. Detecting connection leak
@RunWith(JUnit4.class)
@DBUnit(leakHunter = true) (1)
@Ignore("`shouldFindTwoConnectionLeaks` is failing randomly, seems one of the connections in being closed by another test or DriverManager is returning the same connection.")
public class LeakHunterIt {
@Rule
public DBUnitRule dbUnitRule = DBUnitRule.instance(new ConnectionHolderImpl(getConnection()));
@Rule
public ExpectedException exception = ExpectedException.none();
@Test
@DataSet("yml/user.yml")
public void shouldFindTwoConnectionLeaks() throws SQLException {
exception.expect(LeakHunterException.class);
exception.expectMessage("Execution of method shouldFindTwoConnectionLeaks left 2 open connection(s).");
createLeak();
createLeak();
}
private void createLeak() throws SQLException {
Connection connection = getConnection();
try (Statement stmt = connection.createStatement()) {
ResultSet resultSet = stmt.executeQuery("select count(*) from user");
assertThat(resultSet.next()).isTrue();
assertThat(resultSet.getInt(1)).isEqualTo(2);
}
}| 1 | Enables connection leak detection. |
| If number of connections after test execution are greater than before then a LeakHunterException will be raised. |
8. DataSet export
8.1. Export dataset with @ExportDataSet annotation
@Test
@DataSet("datasets/yml/users.yml") (1)
@ExportDataSet(format = DataSetFormat.XML, outputName = "target/exported/xml/allTables.xml")
public void shouldExportAllTablesInXMLFormat() {
}| 1 | Used here just to seed database, you could insert data manually or connect to a database which already has data. |
After above test execution all tables will be exported to a xml dataset.
| XML, YML, JSON, XLS and CSV formats are supported. |
8.2. Programmatic export
@Test
@DataSet(cleanBefore = true)
public void shouldExportYMLDataSetProgrammatically() throws SQLException, DatabaseUnitException {
tx().begin();
User u1 = new User();
u1.setName("u1");
EntityManagerProvider.em().persist(u1);
tx().commit();
DataSetExporter.getInstance().export(emProvider.connection(), new DataSetExportConfig().outputFileName("target/user.yml"));
File ymlDataSet = new File("target/user.yml");
assertThat(ymlDataSet).exists();
assertThat(contentOf(ymlDataSet)).
contains("USER:" + NEW_LINE +
" - ID: " + u1.getId() + NEW_LINE +
" NAME: \"u1\"" + NEW_LINE
);
}
@Test
@DataSet(cleanBefore = true)
public void shouldExportYMLDataSetWithExplicitSchemaProgrammatically() throws SQLException, DatabaseUnitException {
tx().begin();
User u1 = new User();
u1.setName("u1");
EntityManagerProvider.em().persist(u1);
tx().commit();
DataSetExporter.getInstance().export(emProvider.connection(),
new DataSetExportConfig().outputFileName("target/user.yml"), "public");
File ymlDataSet = new File("target/user.yml");
assertThat(ymlDataSet).exists();
assertThat(contentOf(ymlDataSet)).
contains("USER:" + NEW_LINE +
" - ID: " + u1.getId() + NEW_LINE +
" NAME: \"u1\"" + NEW_LINE
);
}8.3. Configuration
Following table shows all exporter configuration options:
| Name | Description | Default |
|---|---|---|
format |
Exported dataset file format. |
YML |
includeTables |
A list of table names to include in exported dataset. |
Default is empty which means ALL tables. |
queryList |
A list of select statements which the result will used in exported dataset. |
{} |
dependentTables |
If true will bring dependent tables of declared includeTables. |
false |
outputName |
Name (and path) of output file. |
"" |
8.4. Export using DBUnit Addon
DBUnit Addon exports DBUnit datasets based on a database connection.
You need JBoss Forge installed in your IDE or available at command line.
Use install addon from git command:
addon-install-from-git --url https://github.com/database-rider/dbunit-addon.git
-
Setup database connection
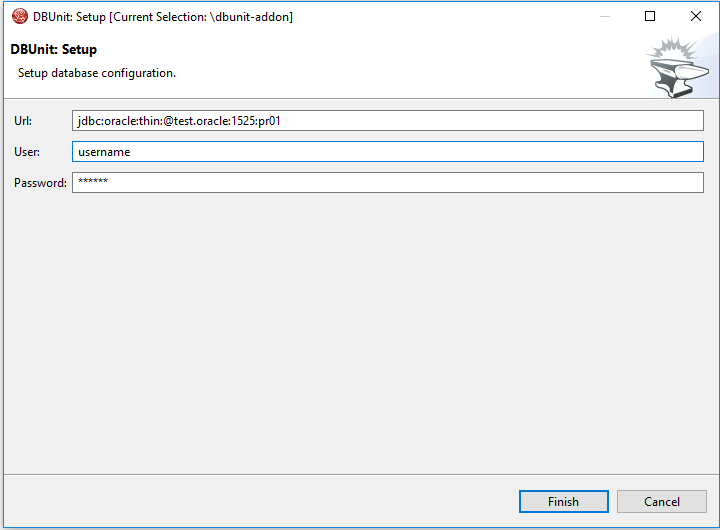
-
Export database tables into YAML, JSON, XML, XLS and CSV datasets.
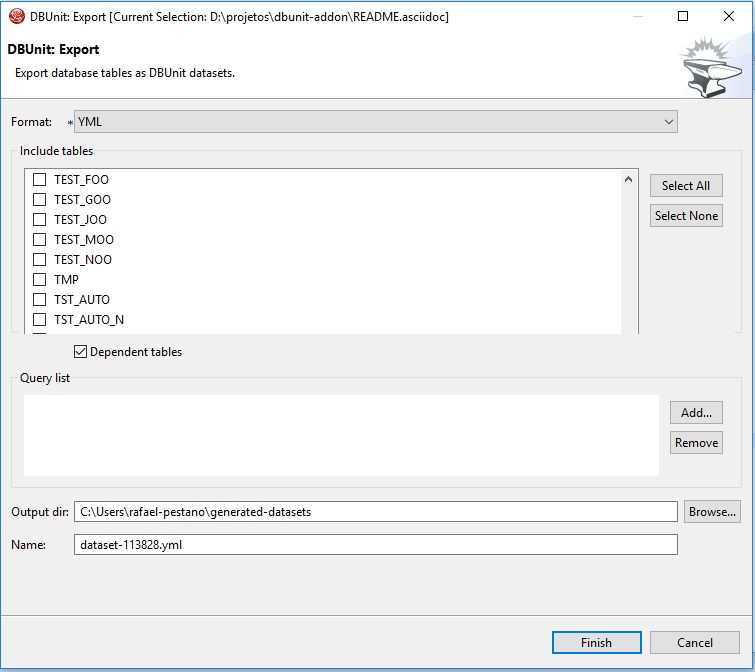
-
Format: Dataset format. -
Include tables: Name of tables to include in generated dataset. If empty all tables will be exported. -
Dependent tables: If true will bring dependent included tables. Works in conjunction withincludeTables. -
Query list: A list of SQL statements which resulting rows will be used in generated dataset. -
Output dir: directory to generate dataset. -
Name: name of resulting dataset. Format can be ommited in dataset name.
9. MetaDataSet
11. DataSet builder
11.1. Create dataset using dataset builder
- Given
-
The following method declaration
- And
-
The following dataset provider implementation
| For more complex examples of programmatic dataset creation, see here. |
- When
-
The test is executed
- Then
-
The following dataset will be used for seeding the database
| yaml format is used only for illustration here, when using DatasetBuilder the dataset is only created in memory, it is not materialized in any file (unless it is exported). |
11.2. Create dataset using dataset builder with column…values syntax
DataSetBuilder has an alternative syntax, similar to SQL insert into values, which may be more appropriated to datasets with few columns and lot of rows.
- Given
-
The following method declaration
- And
-
The following dataset provider implementation
| The columns are specified only one time and the values are 'index' based (first value refers to first column. |
- When
-
The test is executed
- Then
-
The following dataset will be used for seeding the database
| yaml format is used only for illustration here, when using DatasetBuilder the dataset is only created in memory, it is not materialized in any file (unless it is exported). |